Offline Search
Backstory
Many moons ago, when puppies were the oldest animals. I was working on an app with some very unique demands. It was a web app that needed to run entirely offline -- this was back when Apple had just pioneered the app manifest and offline web apps. The app had a large amount of data stored in WebSQL that needed to be searchable. Several attempts had been made to use SQL queries to do this, but the results were never satisfactory.
The Challenge
Beyond the usual challenges of search -- like stemming, synonyms, and relevance -- the search had a unique requirement: it needed to be able to understand measurements and ranges. For example, one of the items in the database could be PVC pipe: 1-1/2 to 3 inches, and that needed to be searchable using any of the following queries:
1.5 inch PVC pipe3" plastic pipe2in. tubing
This was a problem far beyond the reach of a text-based search algorithm. And don't forget, this had to run entirely offline, so we couldn't use any external services or APIs. It needed to be fast on mobile devices, and it had to be compact. Oh... and written entirley in JavaScript.
Build a Knowledge Base
The first step was to identify and classify all of the terms that could be searched. This involved creating a taxonomy of concepts and their relationships specific to the domain of the search data. For example, we needed to know that PVC is a material, Fan Motor is a type of part, and inches are a measurement. We also needed to know that inch, ", and in. are all valid ways to express the same unit of measurement.
This was done by mining the existing data in the database, and then using human expertise to help classify and organize the data. As the data was refined, the concepts and connections were stored in a graph database, which allowed us to easily and quickly traverse the relationships between things.
Convert Text to Concepts
The next step was to cut the text up into meaningful pieces (called tokens). Typically, this is done by splitting the text on spaces and punctuation. But in this case, we needed to do more than that. We needed to recognize measurements and ranges, so we had to write a custom tokenizer that was a little more sophisticated.
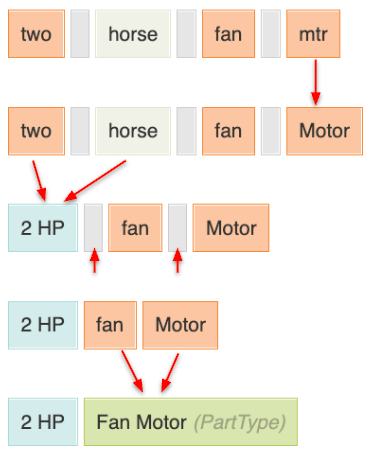
After we have the tokens, we need to make sense of them. This process is called "parsing", and it involves taking the tokens and understanding their meaning in the context of the search. For example, if we have the tokens 1.5, inch, and PVC, we need to understand that this is a measurement of a PVC pipe.
To manage the complexity of this, we created a multi-pass parser. Where each pass would handle a specific job. We ended up with over 2 dozen steps, but for simplicity here are just a few of them (as shown in the image).
- Expand abbreviations
- Identify measurements
- Remove whitespace
- Match words to concepts
Doing this in multiple passes allowed us to keep the code simple and focused on a single task, and it made it easier to test each step independently. It also gave us a useful "escape hatch" for handling edge cases. Later steps could look back at earlier steps and make adjustments if needed (e.g. rolling back changes made in a previous step). And, we could also tag each parsing step based on whether it should run during indexing, during search, or both.
Knowledge is Power
By building a comprehensive knowledge base and a sophisticated parsing system, we now had unified system for: indexing the data, and also for searching. During indexing, we would expand the knowledge base with pointers to the matching items in the database. Then, during search, we convert the search query into a set of concepts in the knowledge base, and then retrieve the matching items from the database based on those concepts.
Aside from being fast and producing great results, this system had the additional benefit of making it possible to do dynamic filtering. For example, if a user searched for a Fan Motor, the system could automatically suggest facets like HP and RPM based on the connections in the knowledge base. This makes for a much more intuitive and powerful search experience, especially on mobile devices, where typing is slow and error-prone. The user could simply tap on a suggested facet to refine their search, rather than having to type a long query.
Fast and Small
The graph structure of the knowledge base was powerful, flexible, and fast. However, it was also large. So, we needed to find a way to make it small enough to fit on a mobile device, and fast enough to run in the browser.
The first breakthrough was the realization that we didn't need bidirectional links at query time. During search, we typically only needed to traverse the graph in one direction. So, we could store the graph as a set of directed edges, rather than a full graph with bidirectional links. And in the rare case that we needed to traverse the graph in the opposite direction, we could store a small set of reverse links for those specific cases.
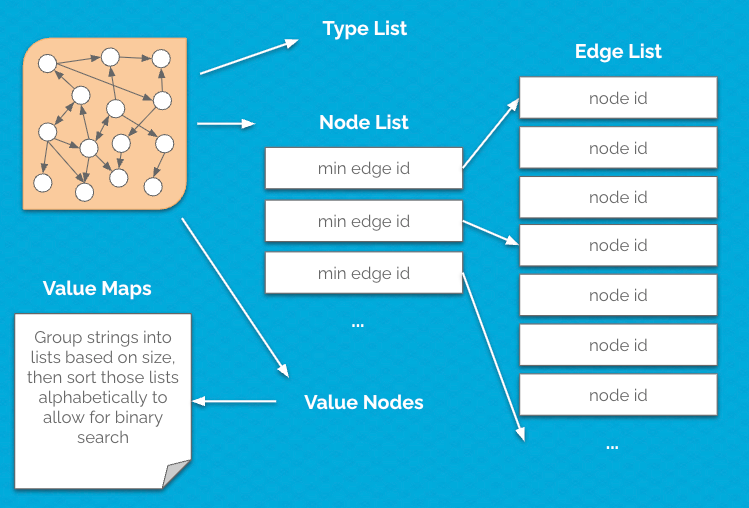
The next step was to decompose the graph into series of subcomponents (as shown in the image).
By grouping the data in this way, we could pack items together into fixed-size blocks that didn't require any additional metadata (or stop bits) to be stored. This also made it possible to use binary search to quickly find items in the lists.
Breaking things apart in this way reduced the storage size of the graph by nearly 85%!
The final optimization for reducing the size was to use a custom binary encoding scheme to store the text data...
And Even Smaller
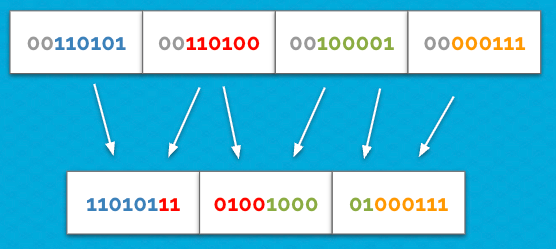
We were able to constrain the set of characters used in our data, so we didn't need 8 bits to store each character. Instead, we could pack the data into 6 bits per character, allowing us to store 4 characters in just 3 bytes.
This reduced the size of our knowledge base by another 20%. And since the data was stored in a fixed-size format, we could use bitwise operations to quickly access the data.
Glossing Over
There was so much more great stuff in the project, like:
- Auto-complete and spelling correction with a weighted trie (pronounced "TRY")
- The comprehensive unit testing suite we built
- Packaging the entire system into a drop-in library
- Building a UI to visualize and explore the knowledge base
- Search & indexing APIs (with single-digit response times) for 3rd party app developers
Results
The final search engine was fast, compact, and surprisingly accurate. We finally had a search engine that made our customers happy, and it was able to run everywhere: on the server, on the client, and entirely offline in the browser.
It's always a joy to work on something where you get rewarded for going "deep in the weeds" on data structures and algorithms, and it was the kind of challenge that rewards you with huge gains when you look at things from different perspectives. Plus, it's the kind of project that helps to justify that expensive Computer Science degree 😉.